前言
ElasticSearch (以下简称为 ES)从名字上看是搜索引擎,实际上除了搜索的作用,ES 甚至还支持上千台服务器分布式部署以及 PB 级别的可靠性存储,适合构建高可用和可扩展的系统。本文从设计的角度探讨 ES 是如何运作且能够支撑如此庞大的数据量的检索和插入。
节点类型
- Master Eligible Node (候选主节点):设置成
node.master=true (default)都可能会被选举为主节点; - Master Node (主节点):由候选主节点选举出来的,负责管理 ES 集群,通过广播的机制与其他节点维持关系,负责集群中的 DDL 操作(创建/删除索引),管理其他节点上的分片(shard);
推荐配置123node.master: truenode.data: falsenode.ingest: false
Tips: 关于 Master 脑裂问题。候选主节点之间出现了网络分区则可能会出现集群脑裂的情况,导致数据不一致或者数据丢失。我们可以通过设置
discovery.zen.minimum_master_nodes设置为(master_eligible_nodes / 2) + 1将避免掉这个问题,弊端就是当候选主节点数由于宕机等不确定因素导致少于(master_eligible_nodes / 2) + 1的话,集群将无法正常运作下去
Data Node(数据节点):很好理解,存放数据的节点,负责数据的增删改查 CRUD;
推荐配置123node.master: falsenode.data: truenode.ingest: falseIngest Node(提取节点):能执行预处理管道,有自己独立的任务要执行,类似于 logstash 的功能,不负责数据也不负责集群相关的事务;
推荐配置1234node.master: falsenode.data: falsenode.ingest: truesearch.remote.connect: falseTribe Node(部落节点):协调集群与集群之间的节点,这里不做过多介绍;
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-tribe.html- Coordinating Node(协调节点):每一个节点都是一个潜在的协调节点,且不能被禁用,协调节点最大的作用就是将各个分片里的数据汇集起来一并返回给客户端,因此 ES 的节点需要有足够的 CPU 和内存去处理协调节点的 gather 阶段。
理解索引(index)
ElasticSearch 是基于 Apache Lucene 开发的,内部自然沿用的就是 Lucene 的倒排索引,关于倒排索引大致的逻辑模型可以参考如下:
假设有两篇文档:
Doc1: Life goes on, impossible is nothing;
Doc2: Life is like a boat;
那么,索引的文件组织逻辑应该是这样的
| 词项 | 文档ID |
|---|---|
| life | Doc1,Doc2 |
| is | Doc1,Doc2 |
| goes | Doc1 |
| on | Doc1 |
| like | Doc2 |
| nothing | Doc1 |
| impossible | Doc1 |
| boat | Doc2 |
对倒排索引以及 Apache Lucene 机制理解了,ES 很多相关的东西很容易深入。
理解分片(shard)
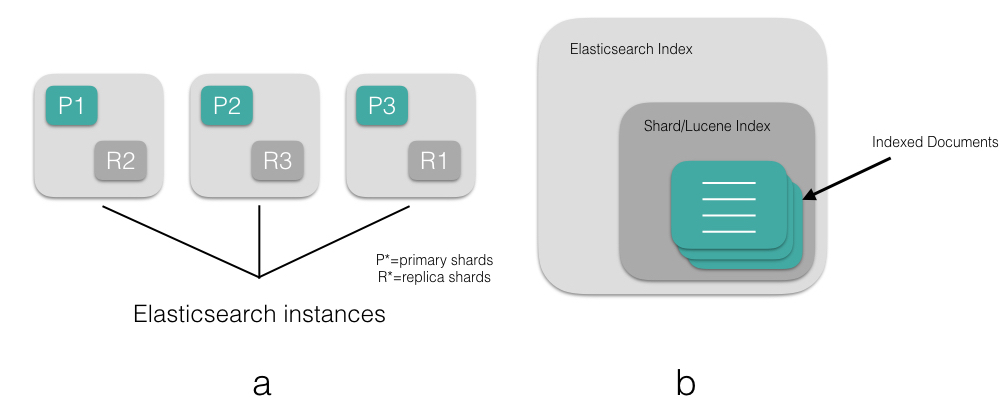
Shard 是 ES 作为分布式存储的一个很重要的概念,ES 是通过 shard 来存储索引(index)的,ES 的 shard 区分为 primary shard 和 replica shard。
primary shard: 每个主分片都有自己的序号,协调节点根据哈希算法将数据路由到对应的主分片上进行读写操作
1shard = hash(document_id or routing parameter) (num_of_primary_shards)replica shard: 副本分片,是主分片的副本拷贝,系统默认副本策略为 Quorum,即写入超过半数副本就可以返回成功,这里后续对副本写入再做介绍。
Zen Discovery & Gossip 算法
ES 的分布式是去中心化的,节点的发现是通过 Gossip 算法来做到的,而后选举节点,让各自节点承担不同角色。这里简单介绍一下 Gossip 算法,假设环境中有两个节点NodeA NodeB,Gossip 算法有三种同步数据(Anti-Entropy)的方式:
① A push B 方式 : A 传 DigestA 给 B,B 接受后回传 DigestA-B 给 A,A 更新 A-B 的数据给 B
② A Pull B 方式:A 传 DigestA 给 B, B 接受后 更新 B-A 的数据给 A
③ A Pull-Push B 方式:A 传 DigestA 给 B,B 接受后 更新 B-A 的数据给 A 并附带 DigestA-B ,A 更新 A-B 的数据给 B
一百个节点下,一个更新的数据传播结果收敛度如图所示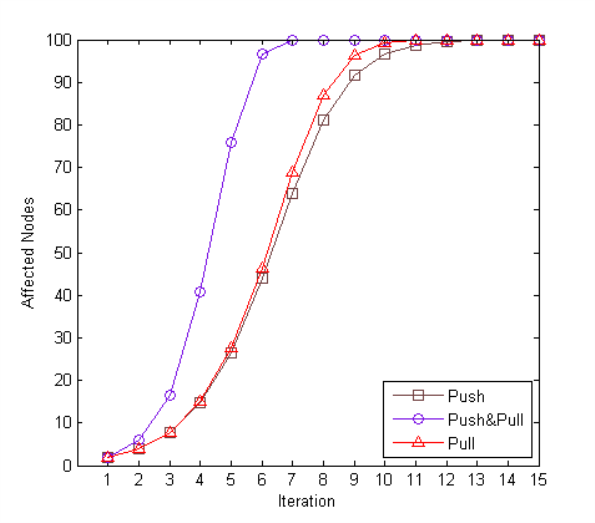
其中可以看到 Pull-Push 的收敛度非常好,在第七次遍历的时候就可以完成100个节点的发现了,ES 正是借鉴了上面的算法实现节点发现(Zen Discovery)的。
由于算法的复杂度为 Lg(N),那么当节点的数目越来越庞大的时候,其发现节点的性能损耗只是呈 Lg(N)递增,换句话说这个算法对节点数目量庞大的集群来说非常受用。
另外关于集群自动发现,不得不提两个参数的区别discovery.zen.fd.ping_timeout 错误检测的超时,在稳定运行的集群环境之中,检测主机与主机之间是否通畅discovery.zen.ping_timeout 仅在选举主节点的时候,这个超时机制才起作用
写操作
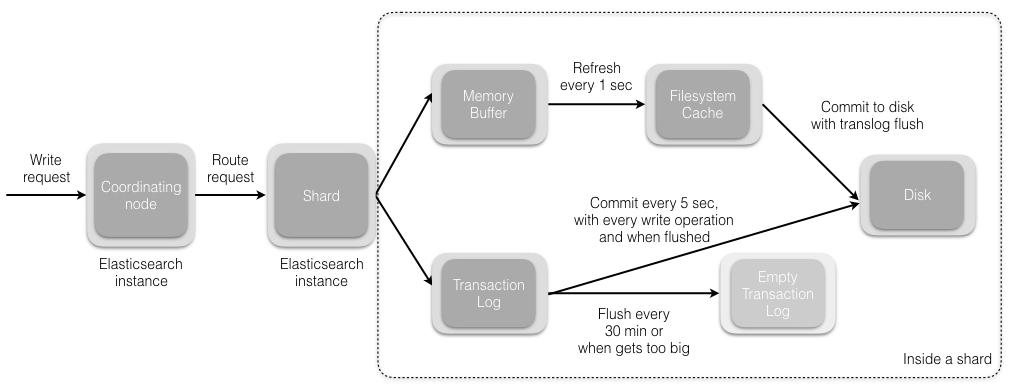
先不考虑副本(replicas),写操作的请求是首先发往协调节点(Coordinating Node),之前说协调节点可能是任何一个你所连上的一个节点,因此每个节点都有可能直接接受客户端的流量,这里相当于做了一次客户端的LB。协调节点根据对 document_id 的哈希计算并取余找到对应的主分片(primary shard)
而主分片本身是分散在集群各个机器之中的,这里就相当于一次主分片的LB。
接下来都是在 shard 中进行操作了,先是写入 Transaction Log(后续会有详细介绍),而后将数据写入内存中,默认情况下每隔一秒会同步到 FS cache 中,FS Cache 拥有文件句柄,因此存在于 FS cache 中的数据是允许被搜索到的(ready for search),这也是 ES 能够实现 NRT(Near-Real-Time)这个特性的原因之一。当然对数据实时性要求高的可以调用 Refresh API。
默认情况下每隔30s 会将 FS cache中的 index 以及 Transaction Log 一并写入磁盘中,当然为了降低数据丢失的概率,可以将这个时间缩短,甚至设置成同步的形式。如果要直接刷盘,参考Flush API
ES 如何写 replicas?
找到对应的 shard 之后,会预先检查 replicas 数量,开始写replicas,此时支持三种策略,quorum、one和 all,默认为 quorum(超过半数副本写入即可返回成功),对应参数 wait_for_active_shards。
Tips: 每一个 replicas shard 中的写逻辑是和 primary shard 一样的。
更新 & 删除文档操作
- 删除: 每个段中维护一个.del 文件,ES 只是逻辑删除文档,在.del 文件中标记为已删除,查询依然可以查到,但是会在结果中过滤掉;
- 更新:引入版本的概念,旧版本的记录将在 .del 文件中标记为删除,新版本的文档将被索引到一个新段(Segment)。
后续会介绍 ES 的乐观并发控制实现。
读操作
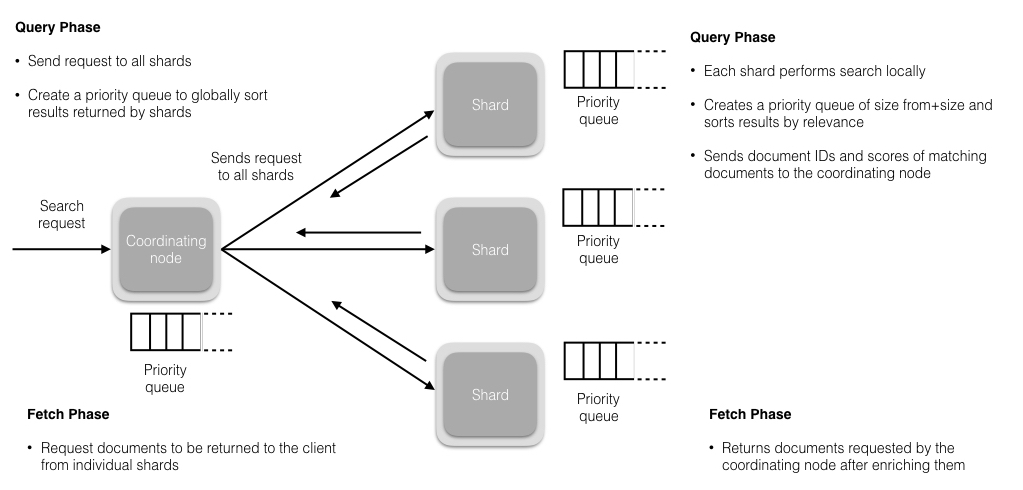
读分为两个阶段,查询阶段(Query Phrase)以及聚合提取阶段(Fetch Phrase)
查询阶段
协调节点接受到读请求,并将请求分配到相应的分片上(有可能是主分片或是副本分片,这个机制后续会提及),默认情况下,每个分片创建10个结果(仅包含 document_id 和 Scores)的优先级队列,并以相关性排序,返回给协调节点。
Tips:查询阶段如果不特殊指定,落入的分片有可能是 primary 也有可能是 replicas,这个根据协调节点的负载均衡算法来确定。
聚合提取阶段
假设查询落入的分片数为 N,那么聚合阶段就是对 N*10 个结果集进行排序,然后再通过已经拿到的 document_id 查到对应的 document 并组装到队列里,组装完毕后将有序的数据返回给客户端。
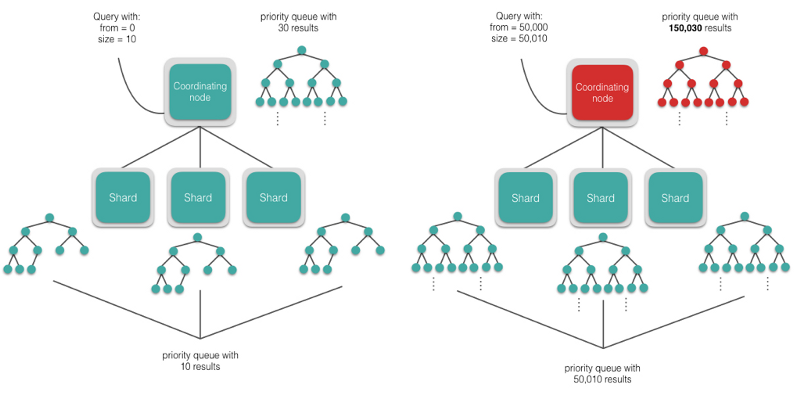
Tips:深度分页查询是有风险的,所谓深度查询就是涉及到大量 shard 的查询时,直接跳页到几千甚至上万页的数据,协调节点就有宕机的风险,毕竟协调节点需要将大量数据汇总起来进行排序,耗费大量的内存和 CPU 资源。所以慎用!尽可能用 Scroll API ,即只允许拿到下一页的信息,不允许跳页的情况出现,会避免这种情况的发生。
小结
这篇文章粗略的介绍了 ES 的节点类型、CRUD 的数据走向和存储的基本逻辑结构以及所用到的一些算法,后续文章会对 ES 有更进一步的理解和认知。
To be Continued…