背景
HBase 基于 Google 的 Bigtable 思想, 附属于 Hadoop 的生态之下,是一个分布式、可扩展、大存储的数据库实现。当你需要随机且实时读写于你的大数据之间,选择 HBase 将会十分受用。
数据结构和基础概念
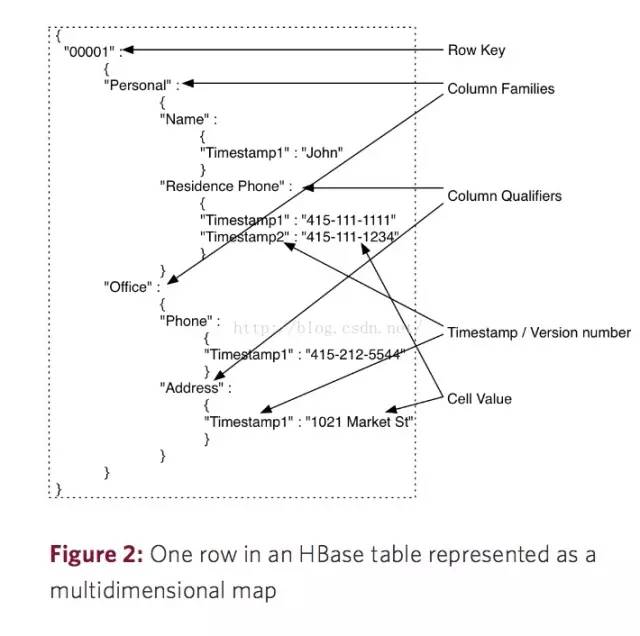

- Table : 表即文件,以下介绍的都是表内元素
- Row Key 行键:可以理解为一个单元数据的 ID
- Column Families 列族 : 定义表的时候需要预先定义,一旦定以后不能轻易修改
- Column Qualify 列标识: 可动态增删字段,也是 HBase 最大的特色
- Cell 单元 :Row Key + Column Families + Column Qualify 为一个单元,存储在单元里的数据叫单元数据
- Timestamp 时间戳: 每个字段下的数据都有一个时间戳,每次更新只是将数据以最新的时间戳覆盖上去,默认取最新时间戳的数据
PUT/GET & SCAN
- put get是操作指定行的数据,需提供 Row Key
- scan 操作一定范围内的数据,需指定开始 Row Key 和结束 Row Key ,如果不指定默认取全部行数据
基本架构及概念介绍
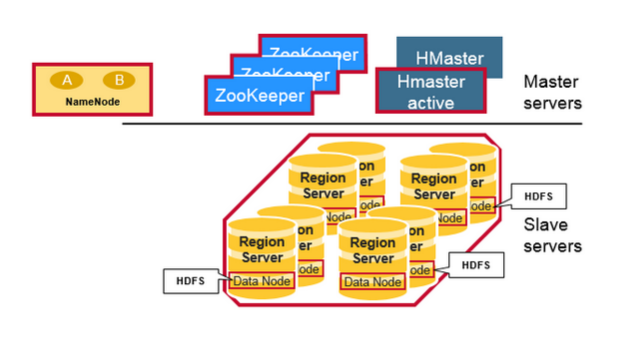
- HMaster: 负责 DDL 创建或删除tables,同一时间只能有一个 active 状态的 master 存在,其余 standby;
- Zookeeper: 判定 HMaster 的状态,谁先创建临时节点谁就激活, 记录 Meta Table 的具体位置等功能;
- Region: 一张 BigTable 的一个分片(Shard),其包含着一个 key space 记录着 key 的开始和结束;
- WAL: 预写日志,持久化且顺序存储,一个 RegionServer 维护一套 WAL;(Eventually Consistency 的保证)
- RegionServer: 一个 RegionServer 中可维护多个 region,一个 region 里包含多个 MemStore(也就是逻辑上的列族,column family) 以及零个或多个 HFiles;
- MemStore: 对应一个 BigTable 的 Column Family,存在于文件缓存中,拥有文件句柄;
- BlockCache: LRU 读缓存,存于内存;(rowkey –> row);
- HFiles: 从MemStore Flush出来的文件,本身是持久化的,存储于 HDFS 的 DataNode 之中,每次Flush生成一个新的 HFile 文件,文件包含有序的键值对序列。后续会介绍 HFile 的数据结构。
写与写缓存(MemStore)
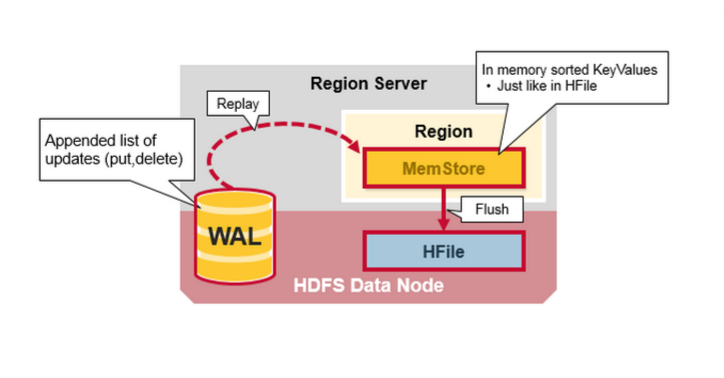
先来看看 Region Server 大致的结构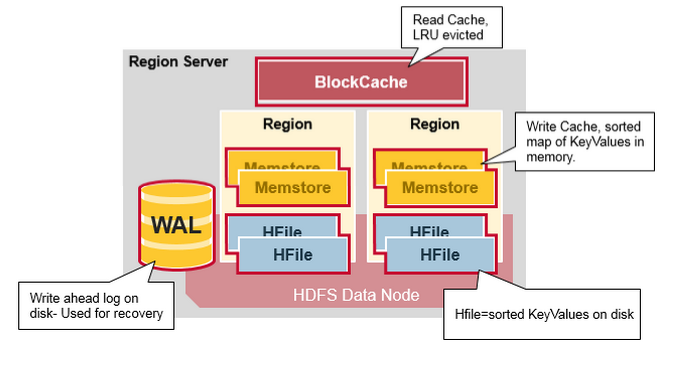
那么写的过程是怎样的呢?
client request —> 写WAL(顺序存储速度快,存于磁盘) —> ack
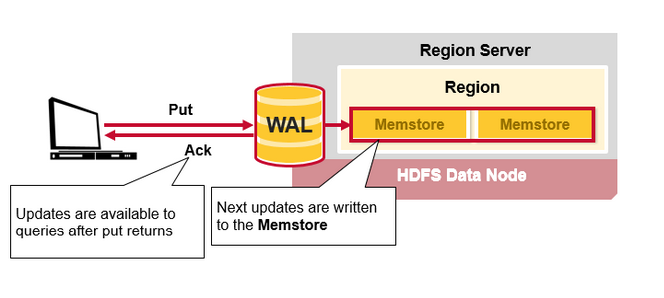
WAL —> MemStore —> flush to HFiles
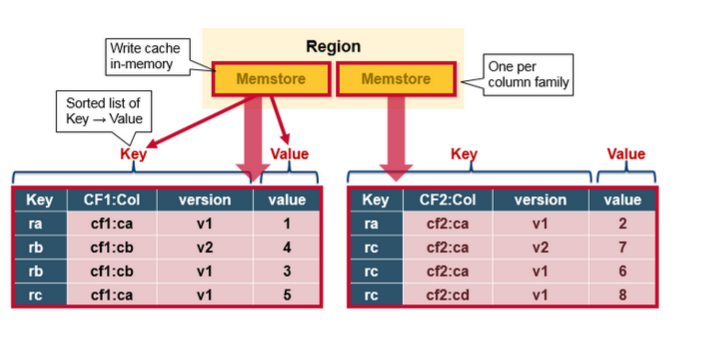
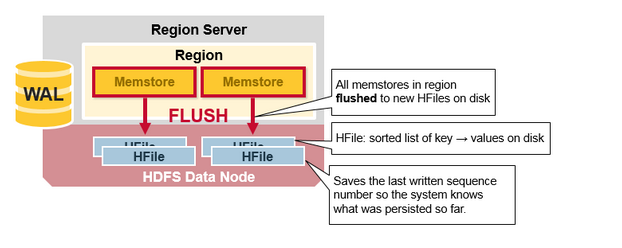
Tips:HBase 中每个 column family 对应一个 MemStore,对应多个 HFiles,也就是包含了多个 autual cells或者 KeyValue 实例,这些KeyValue 是以有序的方式组织成 HFiles 的,顺序且一次性写入,每次 flush 都会生成一个新的 HFile,非常快速。(这里的 CF 是 column family),关于 HFile 的拆分和合并,后续会有交代。
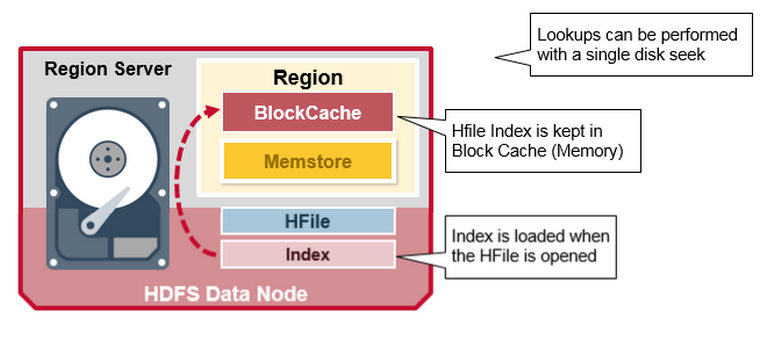
读与读缓存(BlockCache)
在没有缓存的情况下,整个读的流程应该是这样的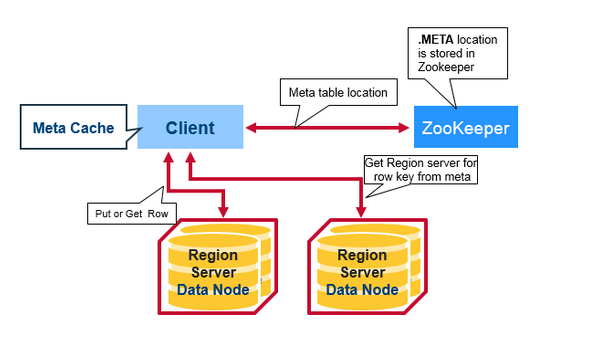
- client 从 zk 里拿 Meta table的访问地址并访问 Meta table;
- client 依据 Meta table 查到 row key想访问的那一个 region server A,并且将其meta缓存起来;
- 从这个 region server A 中获取到 row key 对应的 行(Row);
- 之后的查询都是从 client 缓存读取 meta 信息从对应的 region server 查询;(如果缓存中查询不到对应的数据那么将从第一步重新开始)
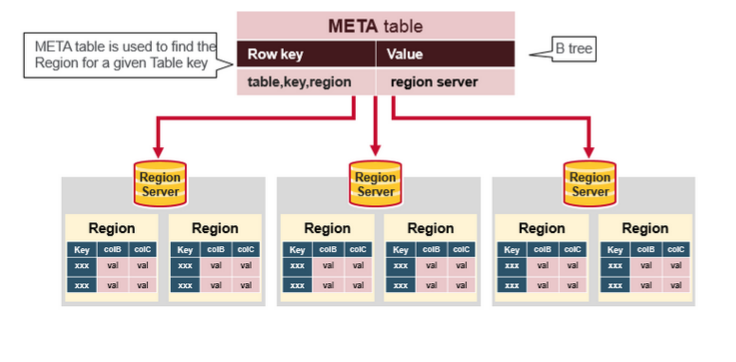
HFiles 数据结构(重点)
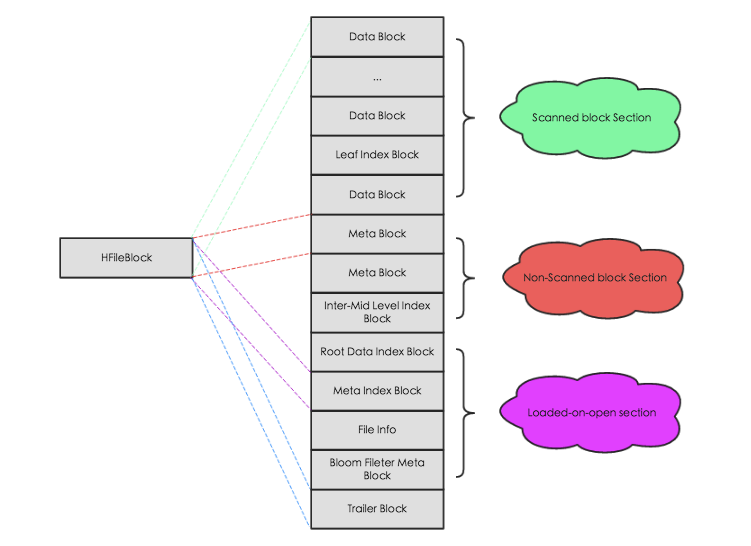
逻辑上包含以下几个部分:
- Scanned block section: 在 HBase 顺序扫描 HFiles 的时候需要被读取的块内容;
- Non-scanned block section: 在 HBase 顺序扫描 HFiles 的时候不会被读取的块内容,主要包括Meta Block和Intermediate Level Data Index Blocks两部分;
- Load-on-open-section: 这部分数据在region server启动时,需要被加载到 BlockCache 中。包括FileInfo、Bloom filter block、data block index和meta block index;
- Trailer: 这部分主要记录了HFile的基本信息、各个部分的偏移值和寻址信息。
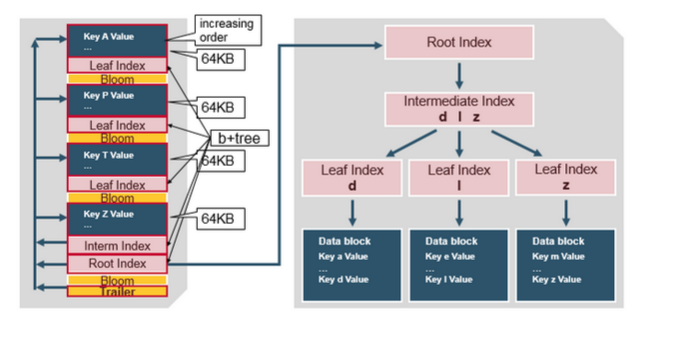
小结:
- HFile 是一次性的,每次 flush 都将生成一个新的 HFile,但后续小文件会合并成大文件。
- HFile 内置了一个 B+ 树索引,当 RegionServer 启动后并且 HFile 被打开的时候,这个索引会被加载到 Block Cache 即内存里;
- Root index 指向 Intermediate Level Data Index Blocks;
- KeyValues 存储在增长中的队列中的数据块里,数据块可以指定大小,默认64k,数据块越大,顺序检索能力越强;数据块越小,随机读写能力越强,需要权衡;
- Intermediate Level Data Index Blocks 指向 Leaf Index,这个索引包含了该数据块下的最后一个 key 值,根据这个 key 就可以确定需要检索的 Data Block了;
- 支持 Bloom Filter(用于排除 没包含指定 rowkey 的 HFile) 与 Time Range Info(用于排除不在指定时间断的 HFile);
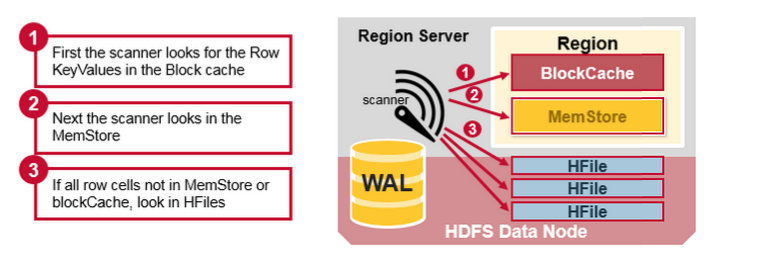
合并读
- 先从BlockCache(读缓存)中找对应的 row;
- 如果缓存里找不到,那就去查询 MemStore(写缓存)找对应的最近的写数据;
- 如果两个地方都没用,那么就会根据 BlockCache 中的 B+ Tree Index(mentioned above)以及 Bloom Filter找 HFile 里的数据;
- 两个缓存无法命中且大量 HFile 未合并的时候,将有可能对很多的 HFiles 进行读操作(这叫 读放大(Read Amplification)。
HBase 压缩策略
Minor Compaction
根据配置策略,自动检查小文件,合并到大文件,从而减少碎片文件,然而并不会立马删除掉旧 HFile 文件。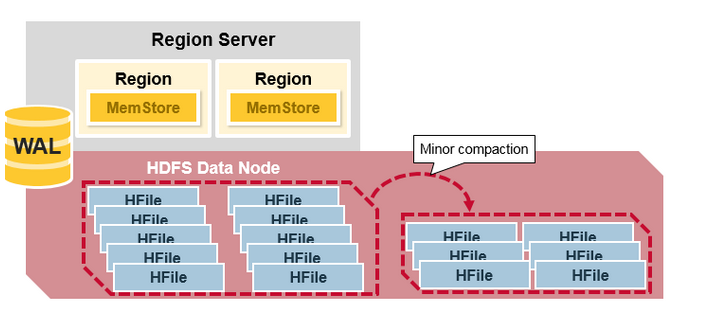
Major Compaction
与上边不同,每个 CF 中,不管有多少个 HFiles 文件,最终都是将 HFiles 合并到一个大的 HFile 中,并且把所有的旧 HFile 文件删除,即CF 与 HFile 最终变成一一对应的关系。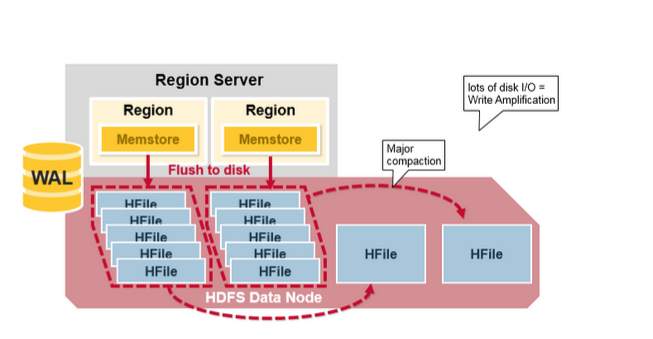
HBase Compaction 改善了读的性能,避免了读放大(Read Amplifiation)的情况出现,但是会导致写放大(Write Amplification),写的时候 IO 会有一定的压力。尤其是一般低峰的时候才会进行 Major Compaction。
Region 的拆分
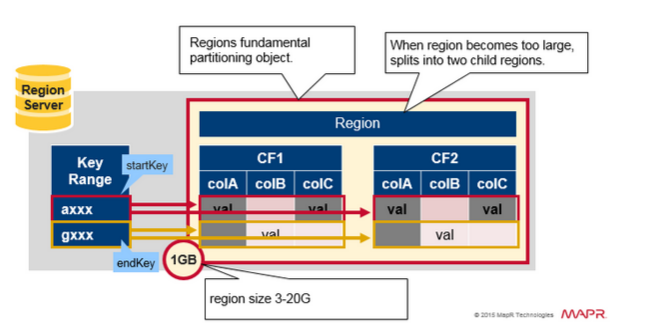
- 一个 Region Server 包含大约1000个 Region(可能属于同一个或者不同的 tables);
- Region 用来响应客户端响应,每个 Region 默认1GB;
- 一个 Table 可以拆分到一个或者多个 Region 之中;
- 一个 Region 包含一个介于开始的 key 和结束的key 之间的,毗邻的有序的行(Row)数据的范围。
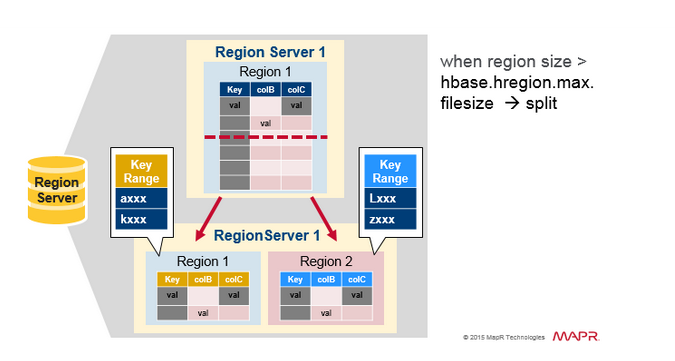
- region 增长过大就会拆分成两个子 region,且子 region 同时被一个 region server 打开,然后将拆分信息上报给 HMaster
- 从负载均衡的角度考虑,HMaster 可能会将新的 regions 分发给其他的服务器。
Tips: HBase 默认给初始 table 以一个 region,数据量到一定程度才会自动拆分,这就会导致一个问题,如果存储少量的热数据在 HBase 里,会导致初始化后的一段时间内集群无法做到负载均衡,不能充分利用整个集群的资源;解决这个问题,只能是预先拆分(pre-split)
以下是当读过于频繁的时候,也会导致自动拆分,以做到读负载均衡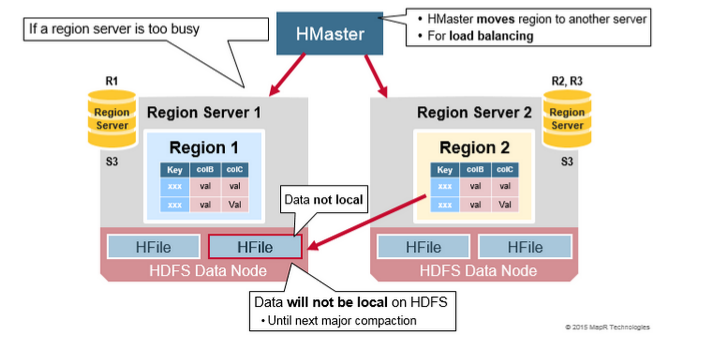
Replication
那么 HBase 是如何从宕机中恢复数据呢?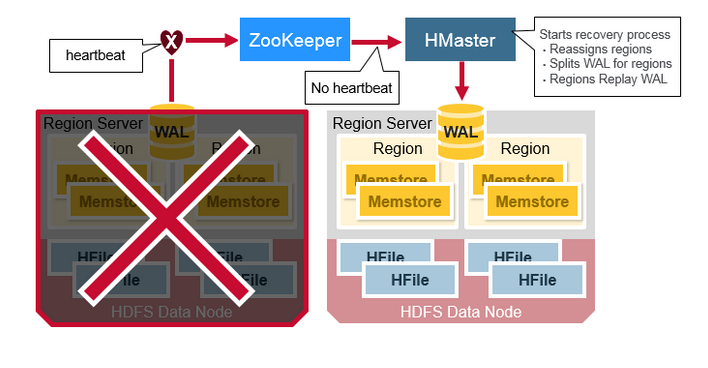
ZK 临时节点消失就判断 RegionServer 已经挂了,这个时候 HMaster 重新指派 regions 到存活的 RegionServer 服务器上,然后拆分 WAL 成几个文件,并且将这几个文件存储在新的 RegionServers 中,这些被分发到的 RegionServers 将会对 WAL files 进行 replay。至此,恢复完毕!
但有一点不解,这里说 HMaster 会将崩溃的 WAL 日志拆分成多个文件传输到存活的 Regions Server之中,然后 replay it。
服务器如果断电崩溃,这样的 WAL 数据是怎么从宕机的服务器中传出来的?
WAL 的写入过程中实际上是包含了 HDFS 的副本拷贝的,WAL 在整个集群里实际上是有副本的存在的,因此即使一台机器挂了,也不影响 HMaster 对宕机节点的 WAL 的获取。
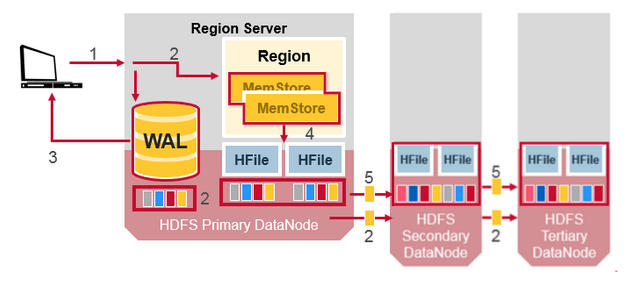
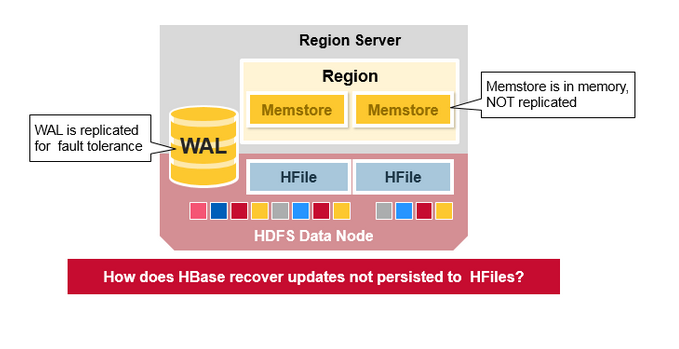
HBase 为 WAL 以及 HFile 创建 HDFS 副本
HBase 表设计要注意的几点
- HBase 只对 Row Key 索引,其余的单元数据的不做索引,因此 Row Key 如何命名很重要;
- 实际生产有时需要对 Row Key 哈希化,使得 Row Key 长度一致,提高数据存储性能,但是牺牲了排序能力;
- HBase 表比关系型数据更加灵活,可以存储任何二进制数据在表中,无关数据类型;
- HBase 只支持行内的原子性保证,因此,横向扩张(动态增加列标识)的表能保持一定的原子性,纵向扩张(同表中多种数据单元共存的设计)能快速简单获取数据,牺牲一定原子性;
- HBase 不支持事务;
- 可以利用列标识来存储数据,例如可以将 A 用户的关注者放到一个 Column Families 中维护,每新增一个关注者就添加一个列标识(Column Qualify);
- 列标识命名长度和列族名字长度都会影响 IO 读写性能,因此应该命名越简洁越好!
Further Reading:
https://mapr.com/blog/in-depth-look-hbase-architecture/#.VdMxvWSqqko
https://hortonworks.com/blog/apache-hbase-region-splitting-and-merging/
http://hbasefly.com/
http://hbase.apache.org/book.html#_preface