Overview
本篇探讨的是 Kubernetes 乃至 Docker 的一个重要话题,网络。我是开发出身,网络知识对我来说就是个新世界的大门。因此关于网络这块我会描述的更加基础,更加易懂,也是为了方便我自己理解。
Docker 的网络基础
以下概念均是从 Linux 的角度来探讨。
网络命名空间
处于不同命名空间的网络协议栈是完全隔离的,且彼此间无法通信,新创建的命名空间只有一个回环设备 lo。这样的隔离确保了容器与容器间的进程号、协议栈以及网络设备等等都是彼此隔离不共享的。同样对于应用层来说,更不需要关心自己所处于哪个命名空间中,这些都是透明无感知的。
当然,所有网络设备只能关联一个命名空间。但是物理设备(连接到硬件的网卡设备)只能关连到 root 这个命名空间之中。对于虚拟的网络设备来说,往往可以在命名空间之间相互移动。
查看一个设备是否能被转移到另外的命名空间中:
|
|
我们可以看到这个回环设备是不能转移的(on 代表不能,off 代表可以转移)。
我们来创建两个命名空间
这两个网络命名空间怎么相互通信呢?
通过 veth 设备对来实现。
veth 设备对
veth 通常都是成对出现的,可以理解为一根虚拟的网线,一头连着一个设备,另一头连接另一个命名空间的设备,当两头连接上后,不同命名空间的网络就可以互通了。
继续我们之前创建的两个命名空间,我们接下来将这两个空间的网络调通。
访问 test-ns 命名空间
生成 veth0 和 veth1,并使之建立关联成为一对。
这时候 ip a 可以看到两个veth 设备,这就相当于一条网线,一侧连着 veth0 另一侧连着 veth1
我们把 veth1 转移给 test-ns2 空间,分配 IP地址给 veth1 并启动 veth1
|
|
给 test-ns 的 veth0 分配 IP 地址,并启动 veth0
|
|
这个时候我们在 test-ns 中 ping 一下 test-ns2 ,发现网络已经通了
如果想知道联通到另一端的设备序号是什么,可以这么执行
通过这个序号去 test-ns2 找到对应的设备
网桥 (Network Bridge)
网桥本身是一个二层设备,意味着他不理解网络层的东西,只能识别物理层以及数据链路层的数据,通过解析 收发 的报文,读取目标的 MAC 地址,与自己维护的 MAC 映射表结合来决策报文转发的端口。(有点类似交换机)
实际网络中,拓扑不可能永久不变,这意味着 MAC 映射表本身是动态的,网桥也要具备一定的学习能力。通过 UDP 广播的做法,对整个集群环境下的 MAC 地址加以学习,更新 MAC 映射表。如果遇到没有学习到的 MAC 地址,会再广播一次,如果再无法找到对应转发的端口,则丢弃该数据包。
以上说的是一个二层设备网桥的处理逻辑。而对于 linux 的虚拟网桥设备来说,除了转发和丢弃报文以外,还可以将数据包丢给 网络层 来处理,进行下一步的分发和路由,为本机所消化。除此之外,其本身还可以被分配一个 IP 地址,因此从这个角度来看,linux 实现的虚拟网桥,实质上也是一个三层设备。
linux 虚拟网桥设备可以将其他设备(如 veth)统统绑定过来,统一管理,veth 本身可以不配置任何的 IP 地址,此时的 veth 就是一个纯链路设备。veth 的另一端分属到各个不同的容器中,充当 容器内网卡的角色,这样一来我可以通过网桥访问本机各个容器了。实际上 docker 的网络解决方案就是这么做的。后面还会提及。
Iptables/Netfilter(NAT)
上一篇文章简单介绍了 Iptables 结合 DNAT 在 kube-proxy 中的应用,用来做服务的负载均衡以及分发。这里对其进行更深入的讨论。
Linux 为 用户 提供了一套机制,以实现自定义的数据包处理过程。
Netfilter 负责内核中执行各种挂接的规则,Iptables 则是在用户模式下运行的进程,负责协助维护内核中 Netfilter 的各种规则表。通过二者的配合来实现整个linux 网络协议栈中灵活的数据包处理机制。
上边提及的技术只能实现单一 host 的容器与容器,Pod 与 Pod 之间的网络通信,但是并没有使得容器端口暴露到宿主机以外的地方,以供外部访问。NAT 可以解决这个问题。
我们来看下容器端口映射到宿主机端口的 Iptables 是什么样子的。通过 iptables-save命令可以看到
|
|
这个配置意味着,往宿主机发送的数据流量中截获到 3306、8080、5000 三个端口的请求,并分别将其转发到对应的容器 IP+port 下。
这便是 Docker 端口映射的实现原理。
路由(route)
上边的技术解决了单一 host 的容器间的访问以及容器端口映射的问题,但是这远远不够。
NAT 仅仅是 IP 的改写和重定向,改写成 172网段的 IP 后如何确保这个 IP 地址一定能访问到 Docker 容器内的数据呢?
对于跨 Host 的网络访问,数据流量是怎么出去的呢?
带着这两个疑问,我们来了解下 route 的机制。
Linux 内部维护了一套路由规则,这个与上边的 Iptables 不一样,路由表能够决定你接下来要走的网络接口,而 Iptables 只能是改写 IP 地址,抑或设置规则丢弃数据包,两者不是一回事。
我们来看下 Kubernetes 一个节点的路由表是怎样的
|
|
这里 Kubernetes 采用的 Docker 网络通信协议是 CNI,这里可以看到该宿主机下的容器访问10.244.1.0/24网段的地址,走的是 cni0接口,如果出现跨网段的情况,例如我要访问10.244.2.2,那么就会路由到 flannel.1 这个接口,从而访问别的宿主机上的容器。
实际上 Kubernetes 中容器的路由发现是动态的,由 Quagga 实现。关于这个,这里暂不做过多介绍。
Docker 的网络实现
Docker 结合现有的底层技术:网络命名空间、网桥、Iptables、路由,实现了资源隔离、端口映射、单一 host 下容器间网络通信等核心功能。了解这些后我激动的画了个大致的图,一目了然。
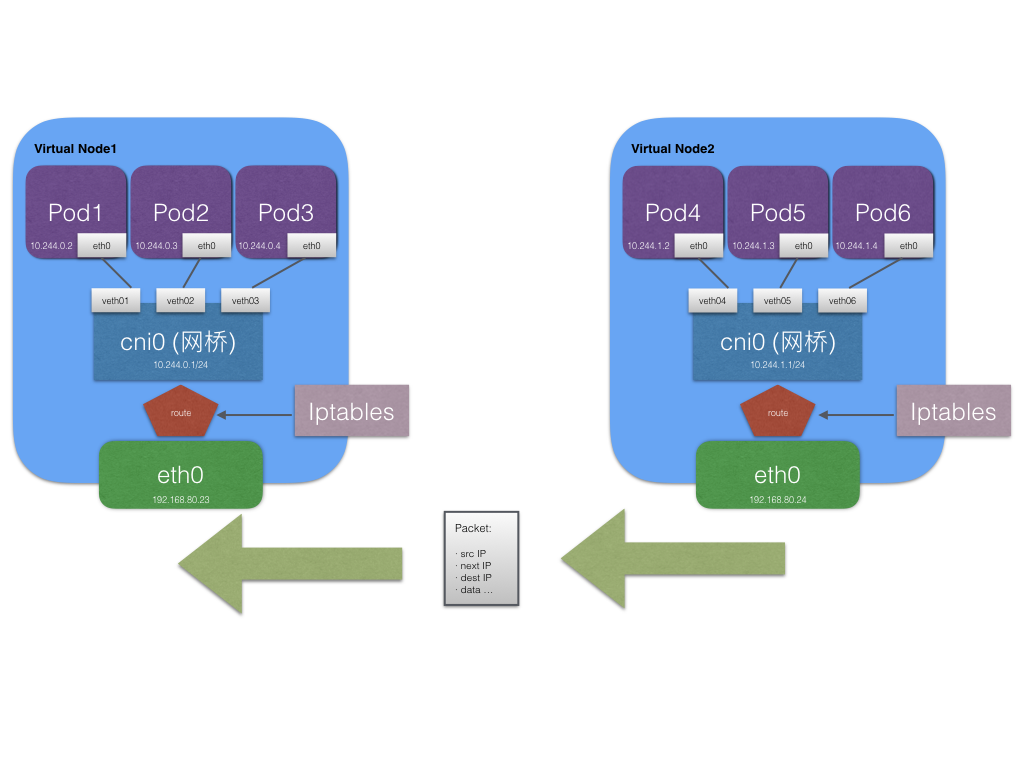
Docker 的网络局限
以简单为美的 Docker 开始发展时并没有一套完整的跨 Host 网络方案,甚至至今 Docker 官方依然不触碰这一块。
而上图中我们不难发现,上边的技术却 似乎 都已经把 Docker 跨 Host 通信的难题给解决了。
实则不然。
这张图上有个逻辑上说不通的地方。不同主机之间容器访问,的确可以拿到目的 IP 地址,但是如何拿到目标宿主机的 IP 呢?换句话说,一个节点上的 Pod 是如何得知不同网段下的 Pod 处于哪个节点呢?
带着这个问题,我们进一步看 Docker 的跨 Host网络解决方案。
Docker 跨 Host 网络解决之道
关于网络解决方案,这里仅仅介绍主流的和值得提及的。
Flannel
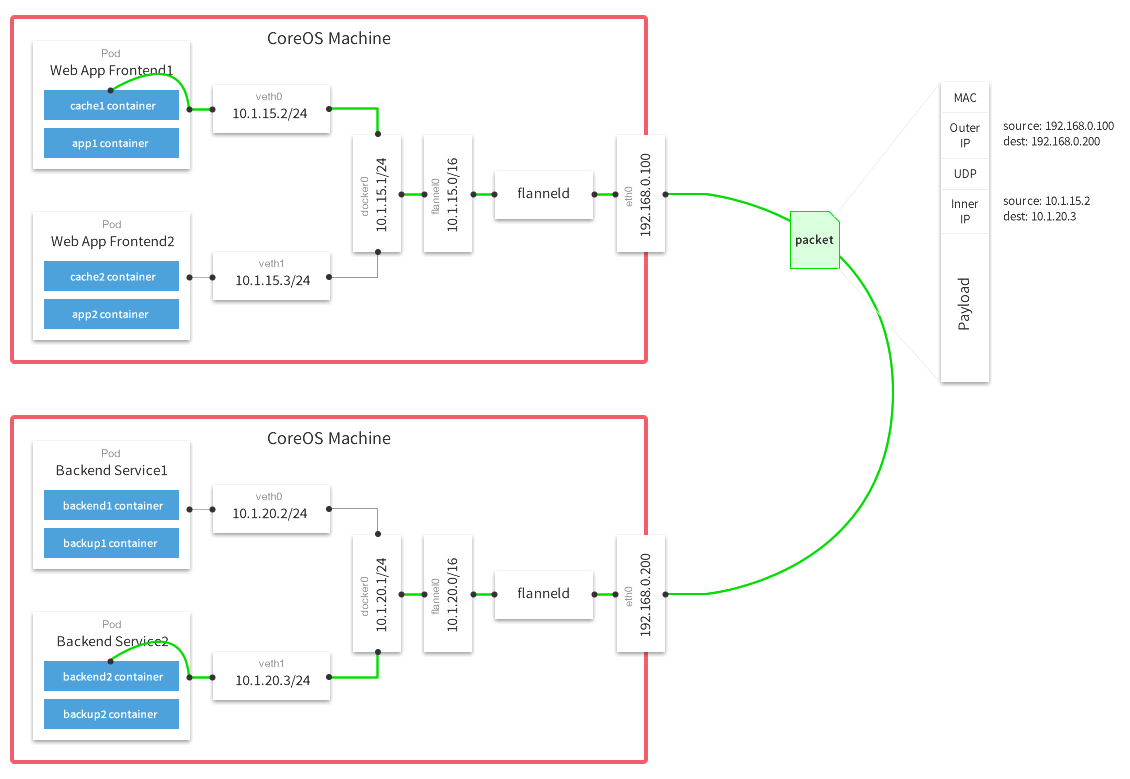
Overlay 的网络方案之一,也是目前较为流行的实现方案。相比上边有漏洞的图,这个的实现就相当完整了,所谓覆盖网络,就是 Docker 的网络层并非实质上宿主机的网络层,对于容器内应用而言所看到的网络层与实际情况是不一样的,实际的加包、传输路由以及解包的操作都是通过这个覆盖网络来实现的,底层用什么协议,于容器而言是透明的。
Flannel 能满足两个基本的要素
- 能够给每个 Node 分配互不冲突的网段,意味着集群内每个容器有着互不冲突的 IP 地址;(指定 docker 启动参数的方式指定网段)
- 能够建立一个覆盖网络,通过这个覆盖网络,能将数据包原封不动传递到目标容器内。(这里传递通常是 UDP 数据包)
图上可以看出,每个机器节点会运行一个叫 flanneld 的进程,这个进程联通了 flannel0 虚拟设备和物理网卡。传输过程中的数据包通过路由规则判断,如果是本网段的访问,就会走 docker0 网桥;如果是跨网段,也就是要跨宿主机访问,就会将数据发往 flannel0。
经过 flannel0 的数据包最终引流到 flanneld 进程里,并将数据包封装成底层通信包,协议包括 UDP、Vxlan等,这里往往用的是 UDP,这个 UDP 的 packet 会根据 etcd 存放的路由表(一般会缓存到主机内存里)找到目的容器 IP 所承载的宿主机 IP,不借助第三方路由设备的前提下,数据包发送到了宿主机上。此时目标宿主机的 flanneld 进程会对 UDP 包进行解包操作,转化成数据包原本的协议,最终根据主机内部路由流入到目标容器中。
容器在中间过程中无法对底层的 UDP 包有所感知,容器之间本身如果是 TCP 互通的也并无任何影响。
不过 UDP 本身是不可靠的,在大流量高并发场景下,可靠性有待测试。
当然这里还涉及到一个路由学习的问题,上边也提及过,etcd 数据库存放的路由表是通过 Quagga 学习来的。
我们可以通过抓包来看看 Flannel 是否真的会导致协议发生变化?
|
|
抓取 flannel.1 网络设备的数据包,理论上来说,其中应该包含大量 Pod IP 相互请求,是容器内流出的数据包。

果不其然,这里包含了 MONGO 和 TCP 等协议的内容,这些都是与应用本身有关的数据包。
我们来抓 eth0的包,看看会有什么
|
|
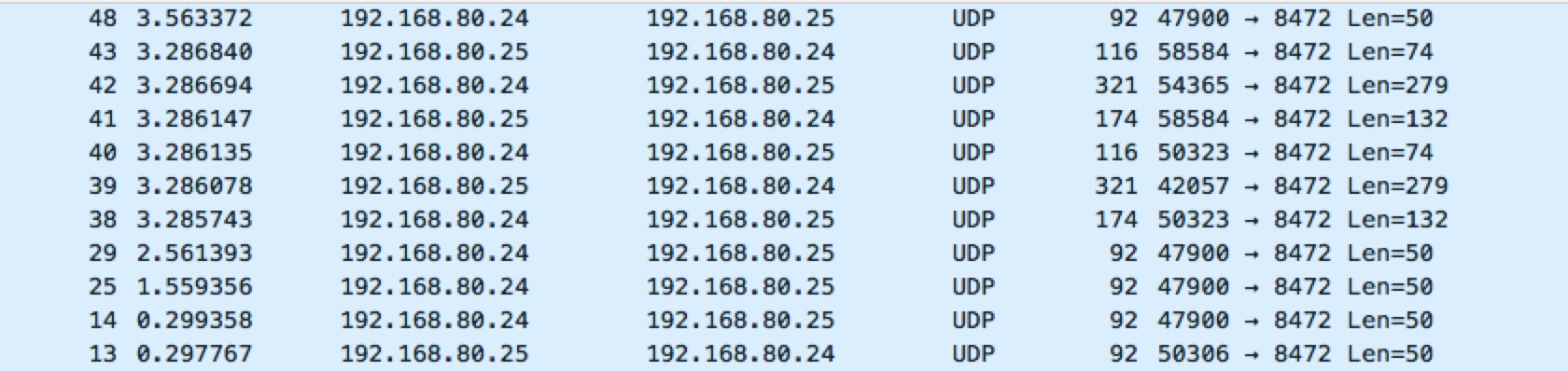
按照上边的说法,flannel 会对 flannel.1 接口的数据重新封装成 UDP 协议,发送到对应的宿主机节点里,实际抓取和理论一致。
Open vSwitch(开源虚拟交换机)
同样是 Overlay 网络方案的一种,也是 OpenStack 的网络解决方案 ,在 IaaS 领域比较常见。
顾名思义,OVS 就是一个虚拟交换设备,用来取代 部分 物理交换机的功能。考虑到在实际的 IaaS 的环境下,如果所有虚拟机的网络请求都流入物理交换机,势必会牺牲交换机性能,影响全局网络。OVS 的出现就是给每一个物理主机提供一个虚拟的交换设备,实现一定程度的网络隔离,避免所有的 VM 流量流入物理交换机。
我们可以利用 OVS 的 GRE 隧道来构建 Docker 跨主机网络,假定我们给 Docker0 分配了我们期望的网段,且每个节点的网段互不冲突。这时,在每个节点构建一个 OVS 网桥,并加入到 Docker0 上。并且在 Docker0 上配置好相关路由项,即超出本机 Docker 网段的 Pod IP 地址的数据包,会转入 OVS br0 网桥之中。
当容器内的应用跨主机访问另一个容器内的应用地址时,数据包先是流入Docker0,因为此时 OVS 网桥是作为 Docker0 的一个接口存在的,因此再转入 OVS br0 网桥,OVS 通过配置好的 GRE/VxLan 隧道,通过桥接物理网卡设备,自然能将数据送达到对应的 remote IP 上,而这个 IP 就是目标容器的宿主机 IP。
我来画个图说明
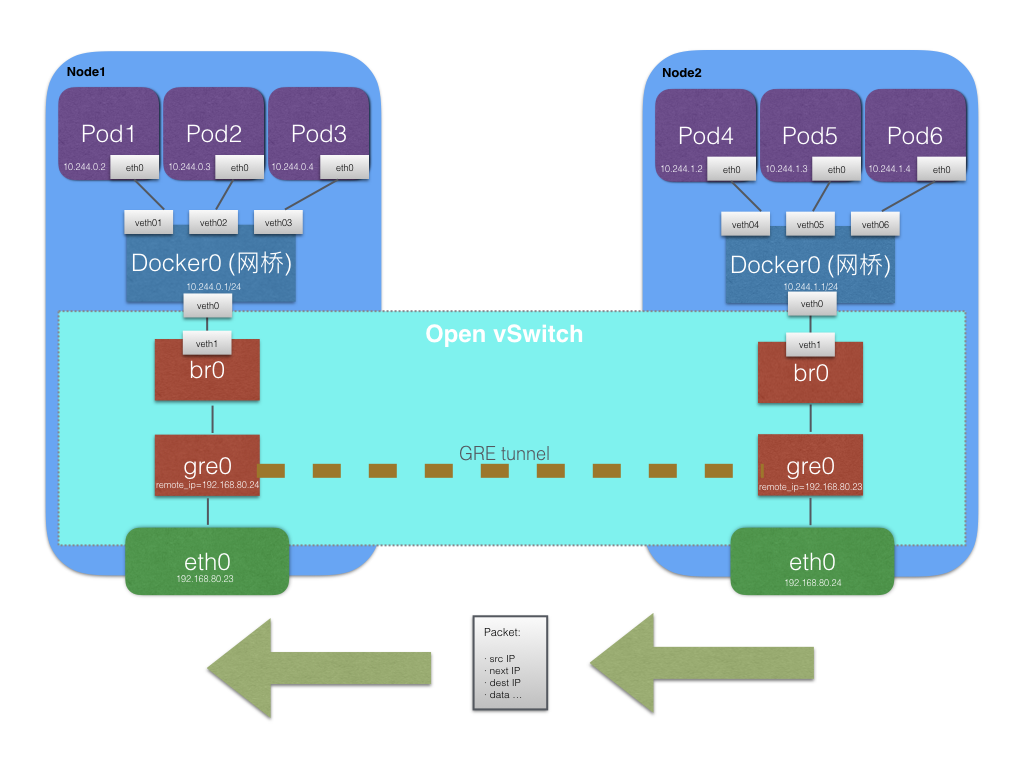
图中明显可以看出,OVS 抽象出了一个三层的交换设备,br0 就是交换机的一个端口,gre 就是隧道,也就是每当新增一个机器节点,就务必得在每一个节点里添加一个 gre 隧道配置,其 remote IP 就是这台新增机器的节点 IP。因此我们可能要借助 Ansible 之类的自动化脚本工具对网络进行构建,否则人工成本太高。
OVS 提供的覆盖网络方案,其本身与 Flannel 相差不大,同样依托于物理网络。在Flannel 中,每个机子都跑一个 flanneld 进程,通过一定的学习手段会将每个机子中的 Pod IP 网段定时上报到 Etcd 存储之中,Etcd 本身是强一致性的,每一次的更新对于整个集群而言是同时感知到的, flanneld 进程会根据 Etcd 中存储的路由信息将数据包发往到对应物理网络的主机上;而 OVS 隧道方案没有这样集中存储的路由表,其路由信息均在每个机器节点上维护,所以不具备物理网络地址发现的功能,因此,从配置上来说会啰嗦很多,需要手动建立 gre 隧道。
OVS 涉及到的内容十分庞大,要一点一点去理解需要花点时间,关于 VxLan 的组网原理也暂时没有深入的了解,会在之后的文章对此有更深入的研究。
直接路由
很好理解,直接对机器节点上的路由项配置和维护,建立 Pod IP 网段与 Node IP 的绑定关系。(可以通过静态路由的配置来实现)
当然为了使得不同节点间的 Pod IP 不冲突,每一个节点都要设置一个独立的 Pod IP 网段。
以配置静态路由为例。
Node1 IP:192.168.80.24
Node2 IP:192.168.80.25
Pod1 处于 Node1上,且 Pod IP:10.244.1.6
Pod2 处于 Node2上,且 Pod IP:10.244.2.3
手动增加两条路由规则:
Node1上
Node2上
那么这两个 Pod 就可以网络互通了。
当然这里涉及到的手动维护成本相当高,每一个节点都要维护一个路由表,工作量相当大,关于这个是可以通过动态路由学习解决的。
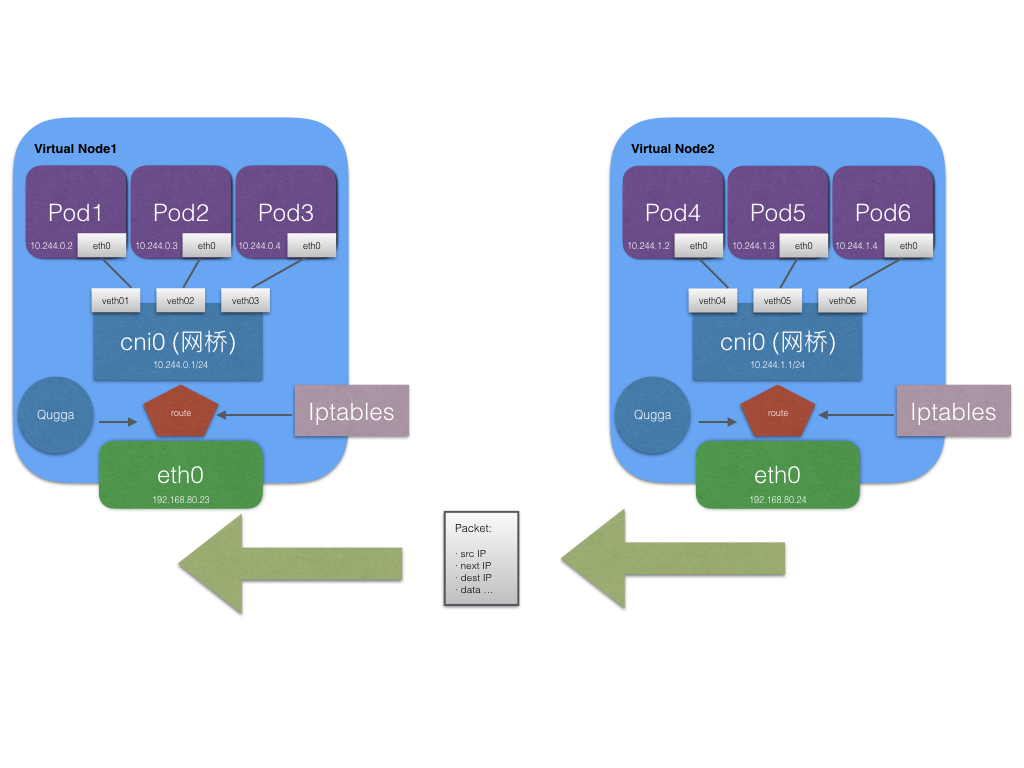
例如上边提及的 Quagga,每一个节点都会运行 Quagga 进程,这个进程的作用是将本机的 LOCAL 路由表通过组播协议传输出去,同时监听其他节点的组播包,这实现了路由信息的交换,完成了一次路由学习。这样一来不需要有很大的工作量就可以实现 Pod 与 Pod 的网络通信了。
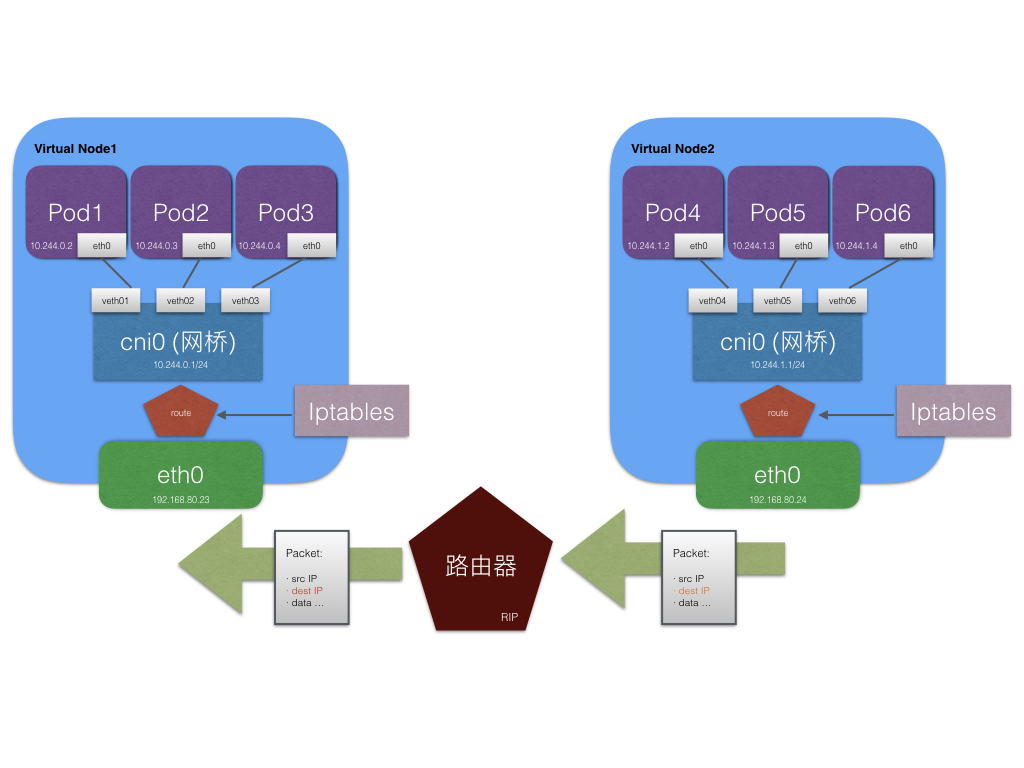
另外的方案是,配置一个独立的路由器,打开 RIP 协议学习路由信息,把 Pod IP 网段与 Node IP 的绑定关系放进来维护,也能实现同样的效果,不仅如此,只要是连入到这个路由器的设备,都可以通过 Pod IP 访问具体的容器了。实现了 K8s 集群外的容器通信。
Calico (重点)
在 CNM 和 CNI 阵营扮演着重要的角色,脚踩两只船。不错的性能、很好的隔离性以及较为安全的 ACL 控制。不仅仅 Kubernetes,他还能在 Openstack 和 Mesos 上跑。
其本身原理也很简单,是 纯三层 的 SDN 实现,没有使用覆盖网络、基于 BPG 协议和 linux 自己的路由机制,不依赖特殊硬件,没有使用 NAT 或 Tunnel 等技术。
Calico 把每个主机节点当作是一个路由器,这样一来利用 linux 内核路由就可以实现容器间跨 host 互联了,等同于和直接路由一般的性能,但大大减少路由配置,因为节点间是可以通过 BGP 协议互相学习的。
我们接下来尝试搭建一个 Calico 网络。
安装过程可以参考 http://docs.projectcalico.org/v2.3/getting-started/kubernetes/installation/hosted/kubeadm/ 这篇文档。
创建网络完成之后我们可以看到这样的列表
当部署 sock-shop 官方样例的时候,我们也可以看到每个机器上的路由也渐渐增多。
(Node1 路由表)
(Node2 路由表)
我们可以看到掩码为255.255.255.192的网段,如 Node1的 192.168.115.128/27和 Node2的 192.168.250.64/27就是挂载在本节点下的 Pod IP 网段,我们可以在该节点下通过 Pod IP 路由到对应的 cali 开头的网络设备上,这个cali开头的设备实际上是 veth 设备对的一端,另一端是直接连入对应的容器内。这样一来网络就通了,此间并没有借助网桥设备。
问题来了,我并没看到跨主机的相关路由。以 DNS 服务为例(DNS 服务需要每个节点每个容器都能访问),其 Pod IP 为192.168.115.135,我们可以发现 node1 本身是可以直接联通 DNS 服务的,然而其余节点一律无法访问。很明显我的配置不正确,导致网络没有完全搭建起来。
发现192.168.115.128/27是 DNS 服务所处的网段,我尝试在 node2 手动配置一个路由,将处于这个网段的请求都转发到192.168.80.23上去
这时候 node2 就能成功联通 DNS 服务了
然而正常使用的 Calico 不应该这么麻烦,这种路由应该是可以通过 BGP 协议习得的。
我们通过 calicoctl node status 命令发现了问题,这三个 IP 地址并不存在系统中,这很奇怪
|
|
查阅文档之后,发现这个问题出现的原因在于 calico 的自动检测 IP 的机制不准确,其默认检测机制是first-found
The first-found option enumerates all interface IP addresses and returns the first valid IP address (based on IP version and type of address) on the first valid interface. Certain known “local” interfaces are omitted, such as the docker bridge. The order that both the interfaces and the IP addresses are listed is system dependent.
This is the default detection method. However, since this method only makes a very simplified guess, it is recommended to either configure the node with a specific IP address, or to use one of the other detection methods.
解决办法是修改 node 的 ip 地址
这样,跨主机访问就彻底通了。
Further Reading
http://www.infoq.com/cn/articles/docker-kernel-knowledge-cgroups-resource-isolation
https://rlworkman.net/howtos/iptables/cn/iptables-tutorial-cn-1.1.19.html#TCPCONNECTIONS
https://wizardforcel.gitbooks.io/network-basic/content/0.html
http://www.sdnlab.com/5889.html
http://dockone.io/article/228
http://docker-k8s-lab.readthedocs.io/en/latest/docker/docker-ovs.html
http://docker-k8s-lab.readthedocs.io/en/latest/docker/docker-flannel.html?highlight=flannel
https://dingtongqin.github.io/technology/openvswitch/
http://www.oolap.com/openvswitch-vlan
http://edgedef.com/docker-networking.html
https://en.wikipedia.org/wiki/Border_Gateway_Protocol
https://www.projectcalico.org/learn/
http://docs.projectcalico.org/v2.3/getting-started/kubernetes/installation/hosted/kubeadm/
http://docs.projectcalico.org/master/reference/node/configuration#ip-autodetection-methods
calico 安装文件
《Kubernetes 权威指南:从 Docker 到 Kubernetes 实践全接触》