之前的文章 《初涉 HBase》 初步介绍了 HBase 底层逻辑,包括 HBase 的基础架构、读写数据流程以及表设计要注意的一些要点。这篇文章着重从 LSM Tree 的角度介绍 LevelDB 的经典实现,并以此为切入点加深对 HBase 的认知。
LSM Tree 是什么
所谓 LSM(The Log-Structured Merge-Tree),即日志结构合并树,是由两个或两个以上存储数据的结构组成的,每一个数据结构各自对应自己的存储介质。
简易模型描述
最简单的 LSM 模型是是被 Patrick O’Neil 提出来的『Two-Level LSM Tree』。这个简易数据结构是由两个树状结构构成,这两颗树分别为 C0 和 C1。C0 比较小,并且全部驻于内存之中,而 C1 则驻于磁盘。一条新的记录先是从 C0 中插入,如果这一次的插入造成了 C0 数据量超出了阀值,那么 C0 中的某些数据片段则会迁出并合并到 C1 树中。其合并排序算法是批量的,由于是顺序存储,速度相当快。
然而通常情况下,每次持久化到硬盘中是一条独立的线程做的,并且生成单独的文件,因此C1树也不止一个文件,当文件数变多的时候,势必导致每一次查询都会涉及到大量文件的打开,每一次文件的打开都是对 I/O 的消耗。为了控制这种 读放大 的情况出现,LSM Tree 必须要考虑小文件合并的问题。
三层模型与合并算法 (Leveled Compaction)

三层模型合并算法只是 LSM 合并算法中的一种。
简单来说,SSTable(Sorted String Table) 的存储是分层的(后续介绍 SSTable 的具体模型),Level 0 中,数据在内存里,往往是以树的结构来展现,当达到一定阀值的时候,其数据以 key 值作为索引,并排列成有序的数据持久化到磁盘上,每个线程在磁盘上对应一个独立的文件或者是一个 key 序列范围的文件集合。如果要执行一次搜索,每一个线程都需要在 Level 0 涉及到的文件中根据指定 key 查相关值。当文件数膨胀之后,每一次 Key 查询将会打开大量的文件(同个 key 可能存在于多个文件中),涉及到大量的 I/O 交互,这样性能很差。这里的检索算法复杂度通常为O(Klg(n)) K 为文件打开数。
在 Level 0 中一个特定的 key 可能会出现在多个不同的文件中(不同版本),大多数应用里都是默认取最新版本的 key-value 数据。而对于 Cassandra 来说,每个 value 对应的是数据库里的一行,而不同版本则对应数据的不同字段。因此查询中可能还需要带版本号查出对应的值,避免不了打开多个文件逐一校对。
三层模型就是从性能角度考虑,将小文件合并成大文件,且除了 Level 0 以外的数据的 key 值是不允许有交集的。
tips:当然三层合并算法并非适用所有业务场景,对于简单的写场景,或者说少量涉及到重复 key 值写操作的场景,可以采用更简单的合并算法,如简单监测文件数量阀值进行合并等。
LevelDB 的 LSM 经典实现
SSTable 与三层模型

SSTable is a simple abstraction to efficiently store large numbers of key-value pairs while optimizing for high throughput, sequential read/write workloads.
而这里的 SSTable 并不是树结构,而是单纯的 KV 结构组成的序列,每一个 key 值的 offset 都存储于 index 之中。
结合三层模型来看,Level 0 的 SSTable 就是 MemTable( C0树 )直接刷进磁盘的文件,允许出现 SSTable 的 key 有交集的情况;Level 1 这一层开始的每一个 key 不允许有交集,也就是说这里的处理逻辑是将 Level 0 中与 Level 1 中的 重复key 归并成新的文件到 Level 1。当触发文件个数的阀值时,Level 1 向上一层再进行合并。
对数据每一层都要进行检索,找出默认的版本数据,通常默认为最新版本。
tips:Ln 与 Ln+1 也不应该有太多重复 key,否则性能也不会太好,因此这里建议设置一定的阀值,当 Ln 与 Ln+1 中的数据 key 重复超过某个阀值的时候,立马合并出新文件。
随机读写
我们知道,随机读写是很吃磁盘 I/O 的,物理上来说要做到性能好的随机读写是很难的。然而如何通过 LSM Tree 来规避这个问题,达到随机读写性能优越的效果呢?LevelDB 是这么约束的。
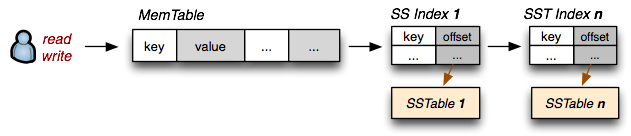
1.磁盘上的 SSTable 索引需要永远加载在内存里;
2.所有写操作,直接写 MemTable (写文件缓存,即内存,保证随机写入速度);
3.读数据的时候先从 MemTable 检索,然后再从 SSTable 的索引中检索;
4.MemTable 周期性 flush 到磁盘中;
5.SSTables 周期性合并;
6.落盘的数据不可变更,更新和删除操作并不是真正的物理修改和删除,只是增加版本号。
写是写内存,因此随机写十分快;读也是读内存里的 SSTable 的索引,并且这里每一个SSTable索引如果用二分法查找,算法复杂度大致在 O(lg(n))与O(n)之间,因此随机读也不慢。
这就是 LevelDB 对 LSM 的经典实现,可以看出,LSM Tree 并不一定维持树结构,甚至可以是与树结构本身无关。
HBase 的 LSM 实现
HBase 则和上边的类似,把 HBase 套用到 LSM 中,Memstore 就是上边的 Memtable,HFiles 就是上边的 SSTables,除此之外,HBase 也和上边对比有一些区别。
WAL 预写日志支持
类似与 binlog 的作用,在写入 MemTable 之前,往 WAL 写入日志,避免宕机出现的数据丢失的情况发生。因此 HBase 算是一个不错的可靠性存储。
这里有个很有趣的地方,某些测试环境下,机械硬盘的顺序写性能会高于对内存的随机写。因此 WAL 的写入性能是非常可观的,我们不必对此过于介怀。
Minor vs Major Compaction
关于 HBase Compaction,这里有一篇不错的文章《About HBase flushes and compactions》,这篇文章告诉我们为什么要做 Compaction,以及如何通过参数来控制 Compaction 的时机和粒度。
接下来我们来看看 HBase 的两种 Compaction 策略,
- Minor Compaction: 根据配置策略,自动检查小文件,合并到大文件,从而减少碎片文件,然而并不会立马删除掉旧 HFile 文件;
- Major Compaction: 每个 CF 中,不管有多少个 HFiles 文件,最终都是将 HFiles 合并到一个大的 HFile 中,并且把所有的旧 HFile 文件删除,即CF 与 HFile 最终变成一一对应的关系。
合并的策略都已经是参数化的。
BlockCache
除了 MemStore(也就是 MemTable) 以外,HBase 还提供了另一种缓存结构,BlockCache。
在介绍BlockCache之前,简单地回顾一下HBase中Block的概念,详细介绍戳这里。 Block是HBase中最小的数据存储单元,默认为64K,在建表语句中可以通过参数BlockSize指定。HBase中Block分为四种类型:Data Block,Index Block,Bloom Block和Meta Block。其中Data Block用于存储实际数据,通常情况下每个Data Block可以存放多条KeyValue数据对;Index Block和Bloom Block都用于优化随机读的查找路径,其中Index Block通过存储索引数据加快数据查找,而Bloom Block通过一定算法可以过滤掉部分一定不存在待查KeyValue的数据文件,减少不必要的IO操作;Meta Block主要存储整个HFile的元数据。
BlockCache 本质上是将热数据放到内存里维护起来,避免 Disk I/O,当然即使 BlockCache 找不到数据还是可以去 MemStore 中找的,只有两边都不存在数据的时候,才会读内存里的 HFile 索引寻址到硬盘,进行一次 I/O 操作。简单来说 LRUBlockCache 是将缓存维护在 JVM Heap 中,实际上 GC 的时候会对其产生影响,于是 HBase 将缓存放到了堆外维护 ,诞生了 SlabCache ,然而 SlabCache 不但不能解决问题反而制造了问题(导致内存使用率变低),已经被淘汰了。阿里大牛经过 SlabCache 的启示开发了 BucketCache,解决了 HBase BlockCache 所面临的痛点,HBase 将 BucketCache 和 LRUBlockCache 搭配使用,称之为 CombinedBlockCache。和之前不一样,系统在LRUBlockCache中主要存储Index Block和Bloom Block,而将Data Block存储在BucketCache中。因此一次随机读需要首先在LRUBlockCache中查到对应的Index Block,然后再到BucketCache查找对应数据块。
关于 BlockCache 参考这两篇文章:
http://hbasefly.com/2016/04/08/hbase-blockcache-1/
http://hbasefly.com/2016/04/26/hbase-blockcache-2/
https://issues.apache.org/jira/browse/HBASE-11323
HFile 的数据结构
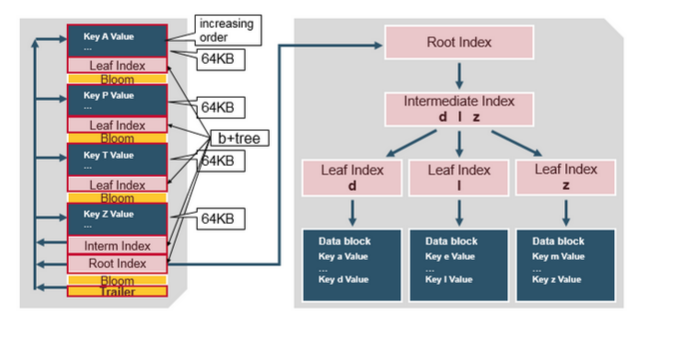
可以看出这里维护的是一个 B 树结构,与 LevelDB 实现的 SSTables 数据结构是不一样的,关于这里的介绍可以参考上一篇文章 《初涉 HBase》
关于 HFile 也可以看看:
http://hbasefly.com/2016/03/25/hbase-hfile/
Bloom Filter
上边的 HFile 文件中包含了一个 Bloom Block,这个是用来做布隆过滤的。Bloom Block 的数据是在启动的时候就已经加载到内存里,除了 Block Cache 和 MemStore 以外,这个也对 HBase 随机读性能的优化起着至关重要的作用。
生成 HFile 的时候,会将 key 经过三次 hash 最终落到 Bloom Block 位数组的某三位上,并将其由0更改成1,以此标记该 key 的确存在这个 HFile 文件之中,查询的时候不需要将文件打开并检索,避免了一次 I/O 操作。然而随着 HFile 的膨胀,Bloom Block会越来越大。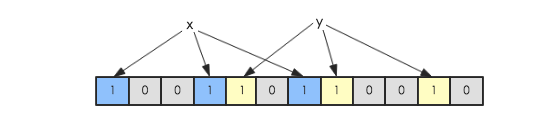
关于 Bloom Filter 可以看这:
http://hbasefly.com/2016/03/25/hbase-hfile/
Further Reading:
https://en.wikipedia.org/wiki/Log-structured_merge-tree
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.44.2782&rep=rep1&type=pdf
https://ggaaooppeenngg.github.io/zh-CN/2017/03/31/从朴素解释出发解释leveldb的设计/
https://blog.acolyer.org/2014/11/26/the-log-structured-merge-tree-lsm-tree/
https://www.quora.com/How-does-the-Log-Structured-Merge-Tree-work
http://hadoop-hbase.blogspot.com/2014/07/about-hbase-flushes-and-compactions.html
http://hbasefly.com/2016/04/08/hbase-blockcache-1/
http://hbasefly.com/2016/04/26/hbase-blockcache-2/
https://issues.apache.org/jira/browse/HBASE-11323
http://hbasefly.com/2016/03/25/hbase-hfile/